Applications are demanding more and more memory at a time when the bandwidth and capacity improvements within a single node in the data center cannot keep up with that demand. The energy costs of moving data play a significant role in the overall data center energy consumption, and as our applications expand beyond the confines of nodes this problem only gets worse. Worse still, bandwidth demands continue to outpace hardware, slowing down applications. The end of Moore's Law has ushered in an age of parallelism and disaggregation, yet frameworks and operating systems have not caught up.
MemOS provides a programming model and framework for building and sharing data (graphs, vectors, or combinations) across networks, interconnects, nodes, and processes without any interposition on the load/store path or serialization during data movement and sharing. It does not require costly coordination between nodes to maintain address spaces, and it reduces software abstraction overhead. MemOS provides APIs for working with memory directly and via typed abstractions. We are in the process of adding support to existing ML/AI frameworks and near-data processing acceleration engines.
Memory was the first to virtualize in the machine and last to virtualize in the data-center. Memory is expensive, and often stranded or squandered, leading to unused memory. Yet as memory pooling grows, the latency between processing and memory grows. This is particularly graph-like processing where round trips from reference chasing can significantly impact application performance and energy consumption. MemOS provides efficient access to Memory Objects, which have the key property that their contents is invariant of the node or memory device on which it is stored. This applies to pointers too -- memory objects break free from the process- and node-centric virtual address model and instead provide a data-centric model. The result is a few key features:
MemOS provides a number of different "levels" of APIs for compatibility. The primary environment is a (mostly) standard Rust programming environment with a custom target atop which existing Rust frameworks can be used, but we are adding support for more languages and frameworks. Existing software is supported a variety of different compatibility levels with different trade-offs.
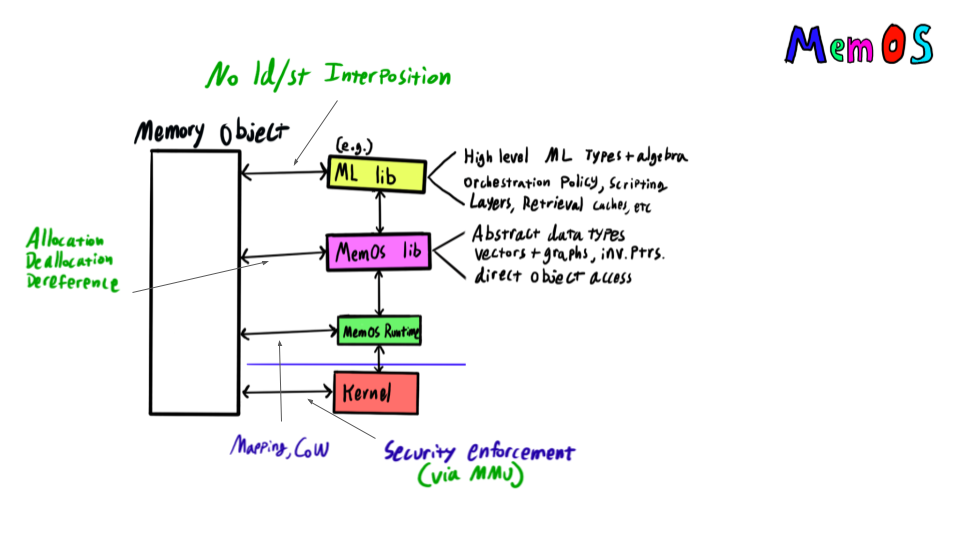
Since MemOS is written in Rust, it provides a safe programming environment for accessing data. In some cases, the safety presents overheads, so MemOS also exposes direct access to object memory with no load/store interposition for low-level implementation of highly efficient data structures and algorithms.
Data structures are often organized either via adjacency (vectors/arrays) or reference (pointers, graphs). Supporting both mechanisms is vital for efficient scaling. For example, indexing becomes vital as data grows and as it is distributed. Vectors enable software to organize data such that is can maximally exploit the underlying parallelism of the hardware. As memory and compute demands grow, both these kinds of "data metaphors" will be vital for scaling.

MemOS uses Invariant Pointers, pointers that are independent of virtual addresses and so mean the same thing everywhere. This key component enables not only offloading complex traversal tasks to near-memory but also fluid movement of data, since one of the key parts of serialization is to get around virtual addresses being so tied and limited.
If you would like to work or partner with us, please reach out! We are interested in access to emerging memory technologies and interconnect technologies, such as CXL, UALink, near-data processing and near-memory accelerators, processing in memory (PIM), processing using DRAM (PUD), non-volatile memory, flash storage, and many others! We are also interested in working with groups to develop support for MemOS in frameworks and libraries.
MemOS is based off the Twizzler Operating System, and uses many of the underlying abstractions and design philosophy.
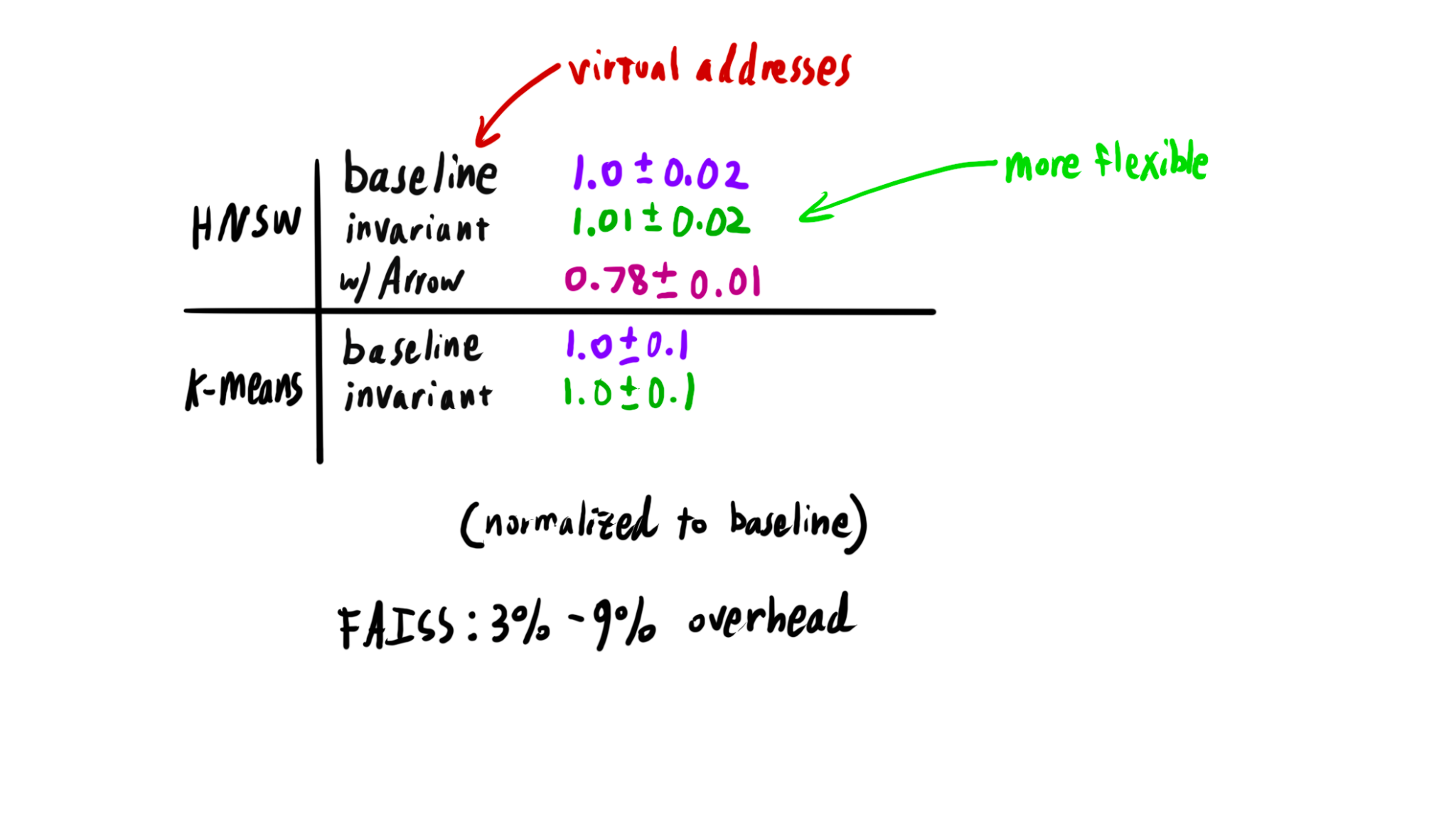
One key class of applications MemOS is targeting is AI -- particularly retrieval augmented generation (RAG). In these tasks, systems typically store huge amounts of vector data that is representative of a document store. This vector data is often indexed via some graph-like data structure for the purpose of finding nearest neighbors for a given query vector. In the case of this example, we implemented Hierarchical Navigable Small World (HNSW) as an appoximate nearest neighbor search over the vectors (a common mechanism). The resulting data structure is a combination of graph and vector data, split among a number of objects. Traditionally, this data structure would be difficult to share or move between nodes since it contains pointers, and would need to be reconstructed. In MemOS, however, the data can be shared directly.
Below is a screenshot of this example that we showed off at OCP Global Summit 2024. In this example, we have two machines sharing a memory pool. In that memory pool is the HNSW data, and both machines are able to use it to perform searches.

Since invariant pointers are not virtual addresses, they do require some additional (cachable) work during translation. However, this has a negligable effect on overall performance, as we can see below. Indeed, a comparable solution to wide sharing in existing frameworks has a higher overhead, and our use of Arrow compute further improves performance.
Databases and data management systems present challenges to operating system APIs, as they tend to demand low-level access to data with strict guarantees from the OS or framework about data movement, eviction, and persistence. MemOS is based on Twizzler, which has a focus on supporting these kinds of needs. In particular, Twizzler provides a (work in progress) safe and efficient programming environment for shared memory, ideal for data management applications. Initial work in the Twizzler project demonstrated the advantages of the Twizzler model by reducing abstraction complexity, depth, and overhead. Below are two graphs showing improvements in SQLite after porting to Twizzler, compared to baseline and an mmap-based key-value store.

The above image shows throughput and the below image shows latency. The Twizzler approach -- modeling data structures directly in-memory, and persisting them -- improves latency and throughput. More details are available here and in our (award winning) presentations.
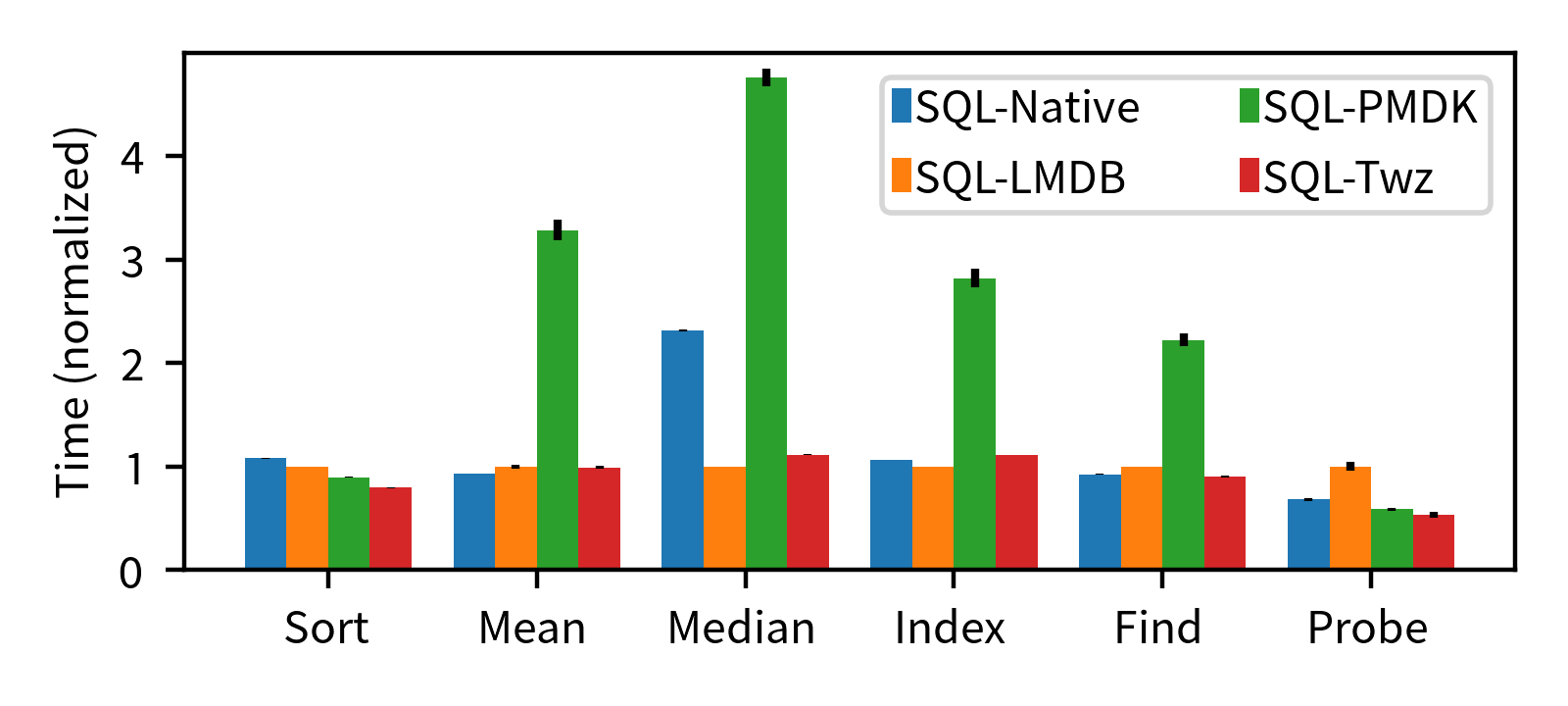
These figures also show a comparison to PMDK, a persistent memory programming framework, which shows the speed and power of invariant pointers. Twizzler started with a focus on non-volatile memory technology but quickly expanded to cover other emerging memory technologies and interconnects.
For more information, check out Twizzler, Daniel's publications and Pankaj's publications. The core philosophy behind this work can be found in Daniel's PhD dissertation.